Unicode چیست
Unicode یک استاندارد بینالمللی برای نمایش و پردازش متن در کامپیوترها است. این استاندارد به هر کاراکتر (حرف، عدد یا علامت) یک کد منحصر به فرد اختصاص میدهد که به آن Point Code گفته میشود. Unicode به این معنی است که هر کاراکتر در هر زبانی، چه فارسی، انگلیسی، چینی و غیره، یک کد خاص خود دارد که در همه جا قابل استفاده است.
مزایای Unicode
پشتیبانی از زبانهای مختلف : Unicode تمام زبانهای دنیا را پشتیبانی میکند و به این ترتیب، کاربران میتوانند در هر زبانی که میخواهند، متن بنویسند و به اشتراک بگذارند.
استقلال از سیستم عامل : Unicode مستقل از سیستم عامل است، یعنی اگر یک متن را با Unicode کدگذاری کنید، در هر سیستم عاملی قابل خواندن است.
سادگی در ایجاد وبسایتها: Unicode باعث شده که ایجاد وبسایتهای چندزبانه بسیار آسانتر شود.
روشهای کدگذاری Unicode
UTF-8 این روش رایجترین روش کدگذاری Unicode است که به صورت متغیر کار میکند. یعنی هر کاراکتر میتواند در یک یا چند بایت ذخیره شود. UTF-8 برای وبسایتها بسیار مناسب است.
UTF-16 در این روش، هر کاراکتر در دو بایت ذخیره میشود. این روش برای سیستمهای عامل ویندوز استفاده میشود.
UTF-32 در این روش، هر کاراکتر در چهار بایت ذخیره میشود که کمتر استفاده میشود.
تفاوت Unicode با ASCII
ASCIIفقط 128 کاراکتر را پشتیبانی میکند و بیشتر برای زبان انگلیسی استفاده میشود.
Unicode دهها هزار کاراکتر را پشتیبانی میکند و برای زبانهای مختلف دنیا مناسب است.
فایل CSV اکسل چیست؟
فایل CSV مخفف Comma Separated Values است که به معنای «مقادیر جدا شده با ویرگول» است. این فایلها نوعی فایل متنی هستند که دادهها در آن با استفاده از کاما (,) از هم جدا میشوند. فایلهای CSV به دلیل سادگی و انعطافپذیری، برای تبادل دادهها بین نرمافزارهای مختلف بسیار پرکاربرد هستند
ویژگیهای فایل CSV :
ساختار: هر سطر یک رکورد را نشان میدهد و ستونها با کاما از هم جدا میشوند.
استفاده: به طور رایج برای جابهجایی دادهها بین نرمافزارهای مختلف استفاده میشود، مانند پایگاههای داده و نرمافزارهای مدیریت مخاطبین
فرمت: میتوانند به عنوان «Character Separated Values» یا «Comma Delimited» نیز شناخته شوند
حجم فایل: حجم فایل CSV به تعداد رکورد و طول هر رکورد بستگی دارد
نمونه ای از فایل CSV را ببینید :
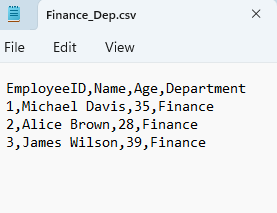
باز کردن یک فایل CSV
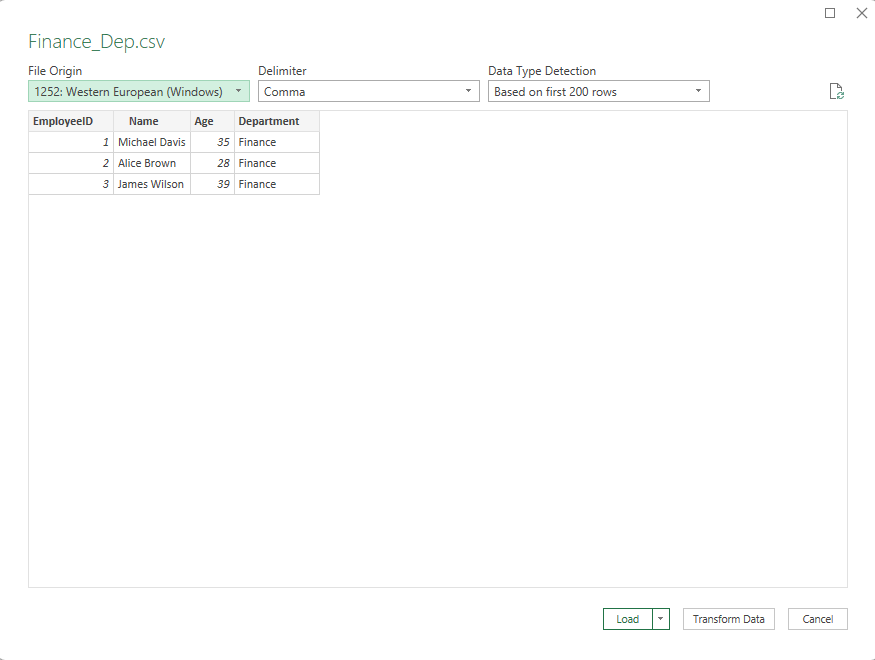
وقتی شما یک فایل CSV را در پاور کوئری باز میکنید، در اولین پنجرهای که با آن مواجه میشوید، بالای سمت چپ نام فایل را می توانید مشاهده کنید کمی پائین تر از نام ، گزینه File Origin وجود دارد. این گزینه به شما کمک میکند تا character encoding یا کدگذاری کاراکتر فایل CSV را مشخص کنید.
اهمیت File Origin
کدگذاری کاراکتر : این گزینه اطمینان میدهد که کاراکترهای موجود در فایل CSV به درستی نمایش داده میشوند. اگر فایل شما حاوی کاراکترهای فارسی، عربی یا سایر زبانها باشد، باید از کدگذاری مناسب استفاده کنید.
استفاده از UTF-8 برای فایلهای CSV که حاوی کاراکترهای فارسی یا عربی هستند، استفاده از UTF-8 به عنوان کدگذاری مناسب است تا اطمینان حاصل شود که کاراکترها به درستی نمایش داده میشوند.
این کدگذاری به طور معمول برای فایلهای CSV استفاده میشود، به خصوص اگر فایل حاوی کاراکترهای غیرانگلیسی باشد. UTF-8 به شما امکان میدهد تا کاراکترهای مختلف را به درستی نمایش دهید.
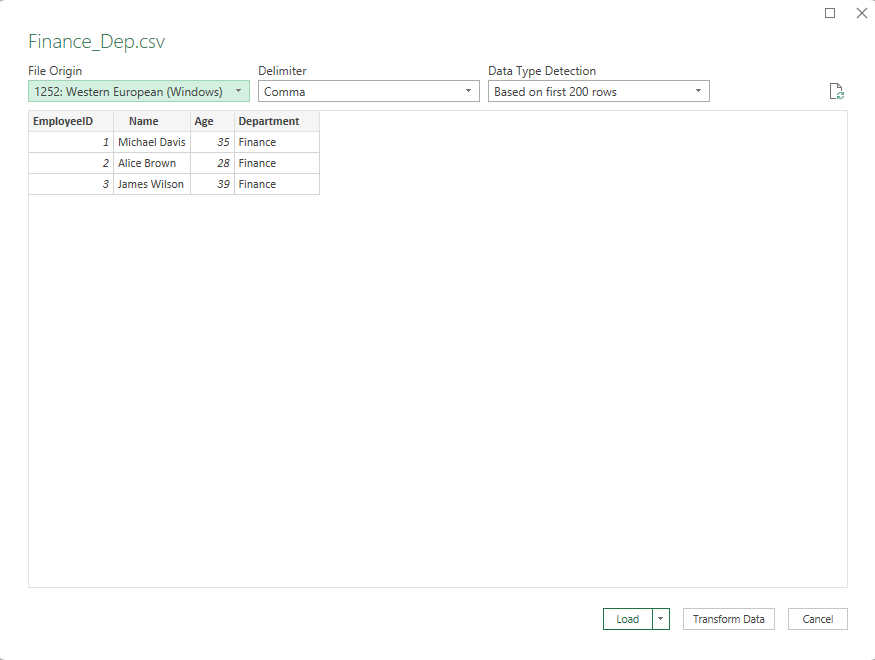
چگونگی استفاده از File Origin
باز کردن فایل CSV : در پاور کوئری، فایل CSV خود را انتخاب کنید.
پنجره File Origin پس از انتخاب فایل، پنجرهای باز میشود که در آن میتوانید File Origin را تنظیم کنید.
انتخاب کدگذاری : اگر فایل شما حاوی کاراکترهای فارسی است، مطمئن شوید که از UTF-8 استفاده میکنید. اگر فایل شما فقط حاوی کاراکترهای انگلیسی است، میتوانید از Windows (ANSI) یا Windows (UTF8) استفاده کنید.پیشنهاد می کنم به ویدئوهای آقای میدانی هم سر بزنید و در آنجا توضیحات مبسوطی نیز از زبان ایشان بشنوید
خطاهای احتمالی :
اگر فایل CSV شما حاوی کاراکترهای فارسی باشد و از کدگذاری مناسب استفاده نکنید، ممکن است کاراکترها به درستی نمایش داده نشوند. در این صورت، کاراکترها به صورت علامت سوال یا کاراکترهای ناشناخته نمایش داده میشوند.
Delimiter در پاور کوئری
وقتی شما یک فایل CSV را در پاور کوئری باز میکنید، در اولین پنجرهای که با آن مواجه میشوید، گزینه Delimiter وجود دارد. این گزینه به شما کمک میکند تا کاراکتر جداکننده دادهها در فایل CSV را مشخص کنید.
اهمیت Delimiter
کاراکتر جداکننده : در فایلهای CSV، دادهها به صورت ستونها هستند و هر ستون با یک کاراکتر خاص از ستون دیگر جدا میشود. این کاراکتر جداکننده معمولاً ویرگول (,) است، اما میتواند نقطه ویرگول (;) یا کاراکترهای دیگر (مانند tab) نیز باشد.
سازگاری با فایلها: اگر فایل CSV شما از کاراکتر جداکنندهای استفاده میکند که با پیشفرض پاور کوئری متفاوت است، باید آن را در این قسمت تنظیم کنید تا دادهها به درستی خوانده شوند.
چگونگی استفاده از Delimiter
باز کردن فایل CSV در پاور کوئری، فایل CSV خود را انتخاب کنید.
پنجره Delimiter پس از انتخاب فایل، پنجرهای باز میشود که در آن میتوانید Delimiter را تنظیم کنید.
انتخاب کاراکتر جداکننده: اگر فایل شما از ویرگول (,) استفاده میکند، نیازی به تغییر نیست. اما اگر از کاراکتر دیگری استفاده میکند، میتوانید آن را در قسمت Custom انتخاب کنید.
تفاوت بین Fixed Width و Custom در Delimiter
در پاور کوئری ، هنگام باز کردن یک فایل CSV یا متنی، گزینه Delimiter به شما کمک میکند تا کاراکتر جداکننده دادهها را مشخص کنید. در این قسمت، دو گزینه Fixed Width و Custom وجود دارد که به شرح زیر هستند: Fixed Width به این معنی است که دادهها در ستونها با عرض ثابت قرار دارند. به عبارت دیگر، هر ستون در یک موقعیت خاص از خط قرار میگیرد و عرض آن ثابت است.
استفاده: این گزینه بیشتر برای فایلهای متنی استفاده میشود که دادهها در ستونهای با عرض ثابت قرار دارند. در این حالت، پاور کوئری بر اساس موقعیت ستونها در خط، دادهها را جدا میکند.
Custom به این معنی است که میتوانید کاراکتر جداکننده را به صورت دلخواه انتخاب کنید. این گزینه برای فایلهای CSV یا متنی که از کاراکترهای خاصی برای جدا کردن دادهها استفاده میکنند، مناسب است.
استفاده: در این حالت، شما میتوانید ویرگول (,) نقطه ویرگول (;) یا هر کاراکتر دیگری را به عنوان جداکننده انتخاب کنید. این گزینه برای فایلهای CSV بسیار رایج است.
نکته : در برخی فایلهای متنی، ستونها با فاصله (Space) از هم جدا شدهاند. بعلاوه ، در ستونهای عددی، اعداد به صورت سه رقم سه رقم با فاصله نمایش داده میشوند، مانند 100 000 000 . در این صورت بهیچ وجه استفاده از Space برای جدا گردن ستونها پیشنهاد نمی شود . در این حالت Custom گزینه خوبی است
Data Type Detection در پاور کوئری
وقتی شما یک فایل CSV را در پاور کوئری باز میکنید، در اولین پنجرهای که با آن مواجه میشوید، گزینه Data Type Detection وجود دارد. این گزینه به شما کمک میکند تا نوع داده هر ستون را به درستی شناسایی کنید.
اهمیت Data Type Detection
شناسایی خودکار: پاور کوئری به صورت پیشفرض نوع داده هر ستون را بر اساس ۲۰۰ سطر اول شناسایی میکند. این کار به شما کمک میکند تا اطمینان حاصل کنید که دادهها به درستی خوانده میشوند.
تنظیمات قابل تغییر: میتوانید تنظیم کنید که شناسایی نوع داده بر اساس کل سطرها باشد، که در این صورت با توجه به حجم فایل ممکن است زمانبر باشد. همچنین میتوانید تنظیم کنید که اصلاً نوع داده را شناسایی نکند.
چگونگی استفاده از Data Type Detection
باز کردن فایل CSV در پاور کوئری، فایل CSV خود را انتخاب کنید.
پنجره Data Type Detection : پس از انتخاب فایل، پنجرهای باز میشود که در آن میتوانید Data Type Detection را تنظیم کنید.
انتخاب روش شناسایی : میتوانید از بین گزینههای زیر انتخاب کنید
Auto Detectاین گزینه به صورت پیشفرض فعال است و نوع داده را بر اساس ۲۰۰ سطر اول شناسایی میکند
Detect from First 200 Rows این گزینه پیشفرض است .
Detect from Entire File این گزینه ممکن است زمانبر باشد، اما اطمینان حاصل میکند که همه دادهها به درستی شناسایی شوند .
Do Not Detect Data Types در این حالت، پاور کوئری نوع داده را به صورت خودکار شناسایی نمیکند و شما باید خودتان نوع داده را برای هر ستون مشخص کنید.
خطاهای احتمالی :
اگر نوع داده به درستی شناسایی نشود، ممکن است در محاسبات یا نمایش دادهها خطا ایجاد شود. برای مثال، اگر یک ستون حاوی تاریخ باشد اما به عنوان متن شناسایی شود، ممکن است در محاسبات مربوط به تاریخ دچار مشکل شوید.
عواملی که باعث میشوند نوع داده ستونها به درستی شناسایی نشود
در پاور کوئری، شناسایی نوع داده ستونها به درستی بسیار مهم است تا دادهها به صورت صحیح پردازش شوند. در زیر به عواملی اشاره میکنم که ممکن است باعث شود نوع داده ستونها به درستی شناسایی نشود:
کد گذاری نادرست : اگر فایل CSV شما با کدگذاری مناسب ذخیره نشده باشد مانند UTF-8 برای کاراکترهای فارسی یا عربی ، ممکن است دادهها به درستی خوانده نشوند و نوع داده به اشتباه شناسایی شود.
حجم داده : اگر فایل CSV شما بسیار بزرگ باشد، ممکن است پاور کوئری فقط از چندین سطر اول برای شناسایی نوع داده استفاده کند. اگر دادههای دیگر در ستونها متفاوت باشند، ممکن است نوع داده به درستی شناسایی نشود.
دادههای ناقص یا نامنظم : اگر دادهها در یک ستون ناقص یا نامنظم باشند (مانند یک ستون که هم شامل تاریخ و هم شامل متن است)، پاور کوئری ممکن است نتواند به درستی نوع داده را شناسایی کند.
تنظیمات پیشفرض : اگر تنظیمات پیشفرض پاور کوئری برای شناسایی نوع داده به درستی تنظیم نشده باشد، ممکن است دادهها به اشتباه شناسایی شوند. برای مثال، اگر تنظیم شده باشد که فقط از چندین سطر اول برای شناسایی استفاده شود، ممکن است دادههای دیگر در ستونها به درستی شناسایی نشوند.
خطاهای انسانی : اگر در هنگام وارد کردن دادهها خطایی رخ داده باشد یا دادهها به درستی فرمت نشده باشند، ممکن است پاور کوئری نتواند به درستی نوع داده را شناسایی کند.
فایلهای CSV با فرمت نامنظم : اگر فایل CSV شما از فرمت نامنظم استفاده کند (مانند استفاده از جداکنندههای مختلف در یک فایل)، ممکن است پاور کوئری نتواند به درستی دادهها را بخواند و نوع داده را شناسایی کند.
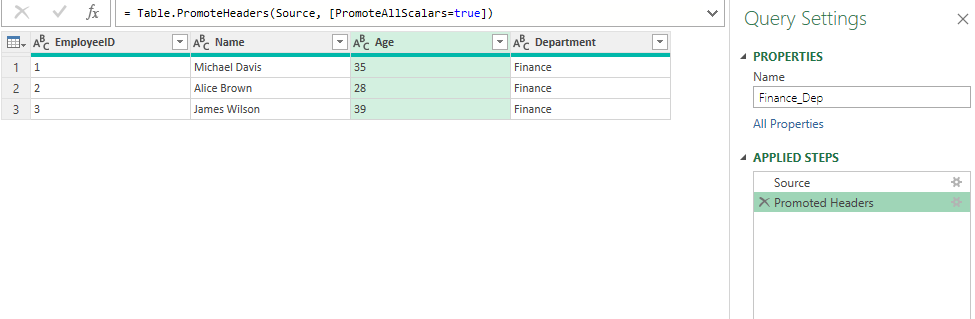
به تصویر زیر برگردیم و گزینه Transform Data را کلیک کنیم تا به محیط ادیتور پاور کوئری برویم
به نظر می رسد جز Load فایل به اکسل کار زیادی باقی نمانده . مرحلهء Changed Type ی که پاور کوئری انجام داده بود پاک کردم در اینجا اصلا نیازی به این Step نداشتیم زیرا ستونی که روی آن محاسبه انجام شود نداریم پس بهتر است جنس همه ستونها Text باشد
ترکیب چند فایل CSV
اگر میخواهید چند فایل CSV را ترکیب کنید، میتوانید از گزینه From Folder استفاده کنید.
در منوی Data، Get & Transform Data > Get Data > From File > From Folder را انتخاب کنید.
مسیر فولدر حاوی فایلهای CSV را انتخاب کنید.
به پنجره ای در تصویر می بینید منتقل می شوید فقط کافیست روی Transform data در پائین صفحه کلیک کنید
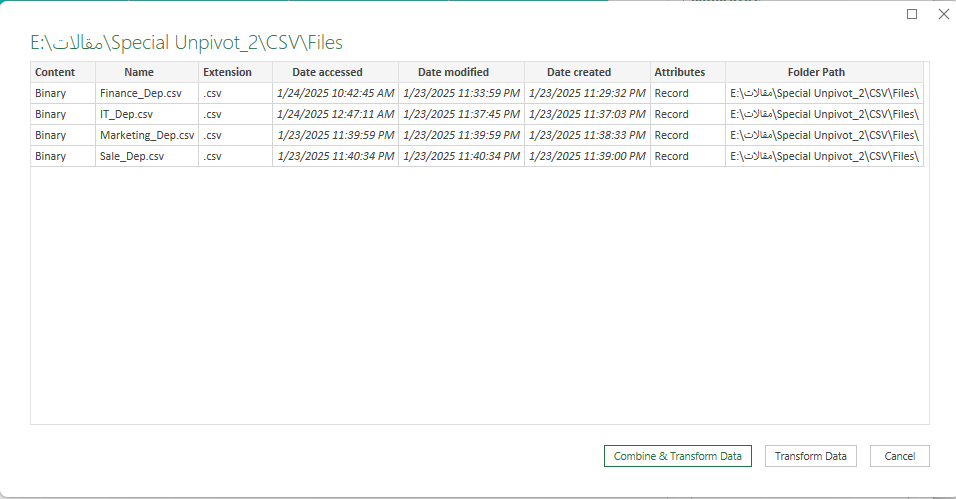
حالا در محیط پاور کوئری هستیم اگر در بخش خالی سلول اول در ستون Content کلیک کنید با تصویر زیر روبرو خواهید بود
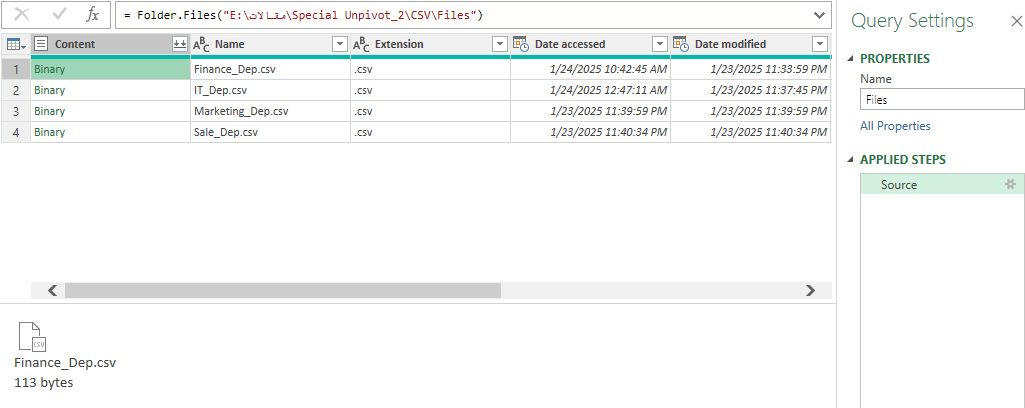
تابع Csv.Document برای تبدیل محتوای CSV به جدول استفاده میشود.
همچنین، میتوانید از تابع Table.TransformColumns برای تغییر آیتمهای یک ستون استفاده کنید . تغییر روی آیتم های یک ستون در اینجا یعنی همان تبدیل محتوای CSV به جدول . پس یک Step اضافه کنید و کد زیر را در آن بنویسید
Table.TransformColumns(Source, {"Content", Csv.Document})
نوشتن کد به شکل دیگر:
میتوانید کد را به شکل زیر نیز بنویسید:
Table.TransformColumns(Source, { "Content", each Csv.Document (_) } )این کد محتوای سلولهای ستون "Content" را به جدول تبدیل میکند. من ترجیحا با دومی ادامه خواهم داد زیرا چنانکه در تصویر می بینید سر ستونها در جای خود قرار ندارند و ترفندی و تابعی لازم است تا آنها را تنظیم کند
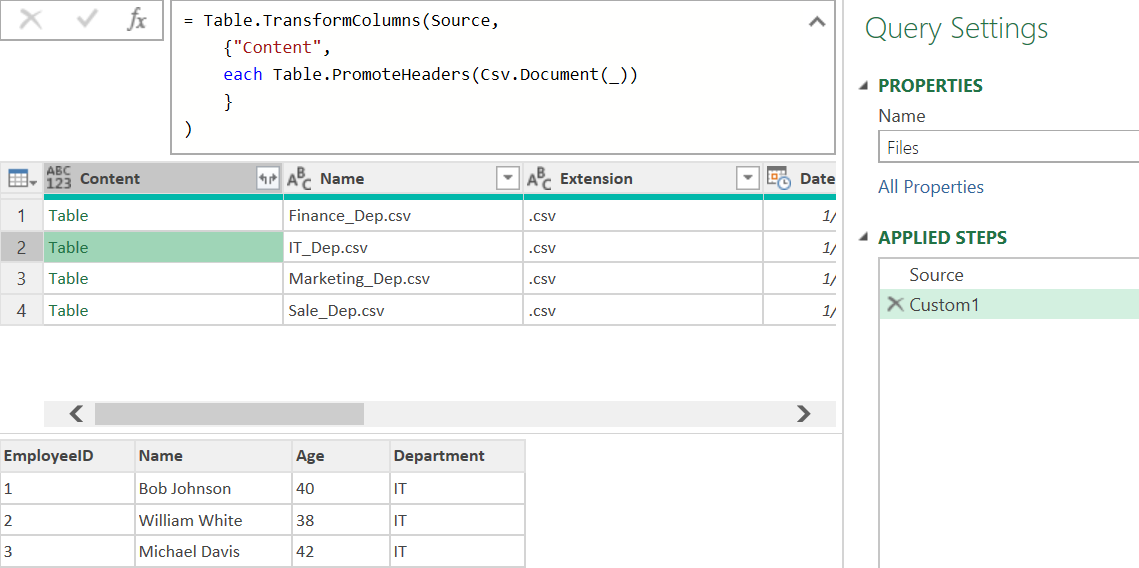
تنظیم سرستونها:
برای تنظیم سرستونها ، لازم نیست مرحله جدیدی Add کنید فقط کافی ست کد بالا را به شکلی که می بینید تغییر دهید
با این کار سرستونها در جای خود قرار میگیرند.
Table.TransformColumns ( Source,
{ "Content", each Table.PromoteHeaders ( Csv.Document ( _ ) ) }
)
بر روی ستون Content کلیک راست کرده و گزینه Drill Down را انتخاب کنید. بعد از استفاده از این گزینه با تصویر زیر مواجه می شوید .
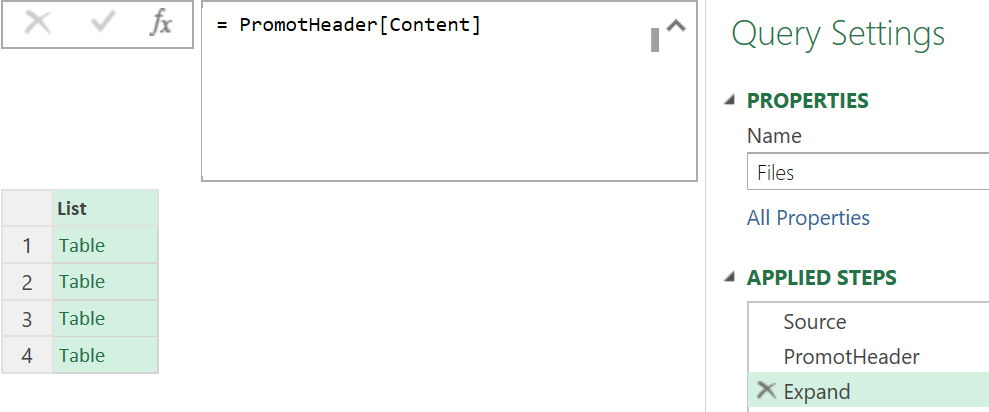
باز هم لازم نیست Step ی اضافه کنید فقط کافیست به ابتدای کدی که در فرمول بار است تابع Table.Combine را بیافزائید
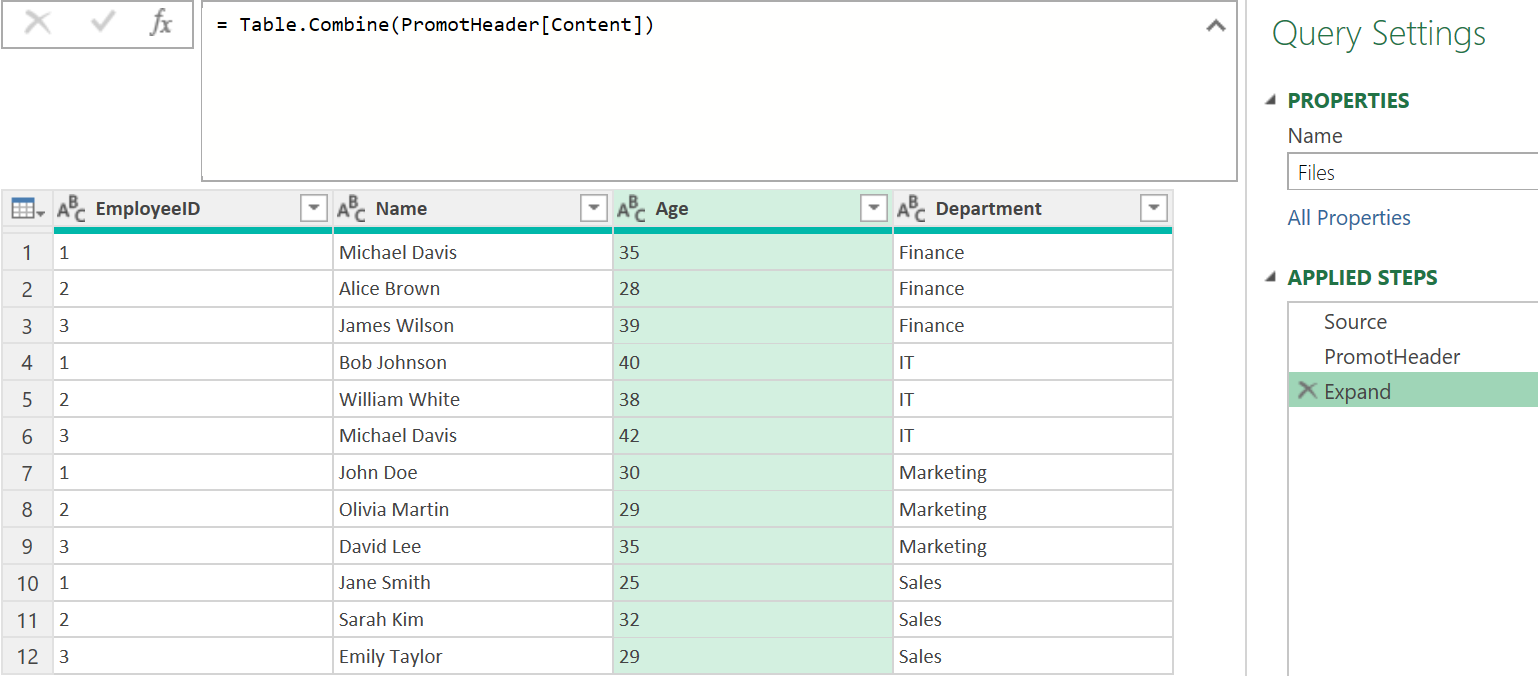
فایلهای Text و CSV وقتی بیش از 1048000 رکود داشته باشند در اکسل جا نمی شوند و نمی توان آنها را در اکسل نمایش داد . بعنوان مزایای پاور کوئری می توان به پردازش انبوه ، سادگی استفاده ، اتوماتیک شدن کارها ، سرعت و دقت اشاره کرد . لابد می پرسید با 4000000 داده چه کنیم ؟ شما بگوئید ، صرف داشتن چهار میلیون داده در هر نرم افزاری به چه کار می آید . فرض کنید در این صفحه هستید
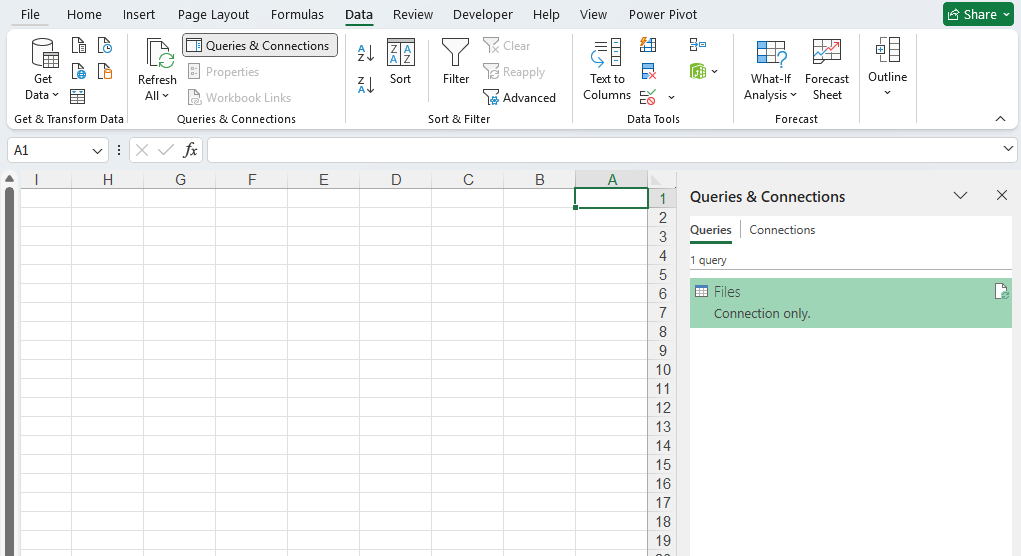
روی Files کلیک راست کنید و Load To را برگزینید و در پنجره جدید تیک PivotTable Report را بزنید و OK کنید
حالا اینجا هستید و می دانید که PivotTable قدرتمند ترین ابزار تجمیع داده است
شما را با پردازش و ایجاد گزارشات مدیریتی ( حتی نمودارها ) از میلیونها داده به خدا می سپارم
به عنوان اولین نفر، تجربه یا دیدگاه خود را بنویسید!